이전 글에서는 JSP 기반 로그인 시스템을 구축하면서 쿠키와 세션, DB 연동까지 구현했습니다. 이번에는 이 시스템을 한 단계 발전시켜 다음과 같은 기능을 추가했습니다.
- DB에 회원 정보 등록 (회원가입 기능)
- 비밀번호 암호화 (SHA-256)
- 로그인 실패 시도 횟수 제한 처리
1. 회원가입 기능 (DB에 사용자 등록)
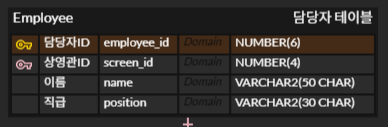
1-1. 사용자 테이블 설계
MySQL Workbench에서 다음과 같은 테이블을 생성합니다.
CREATE TABLE user (
id VARCHAR(50) PRIMARY KEY,
pwd VARCHAR(255) NOT NULL,
name VARCHAR(50),
fail_count INT DEFAULT 0
);1-2. 회원가입 폼 (register.jsp)
<form action="register" method="post">
ID: <input type="text" name="id"><br>
PWD: <input type="password" name="pwd"><br>
이름: <input type="text" name="name"><br>
<input type="submit" value="회원가입">
</form>1-3. RegisterController.java
@Controller
public class RegisterController {
@Autowired
JdbcTemplate jdbcTemplate;
@RequestMapping(value = "/register", method = RequestMethod.POST)
public String register(String id, String pwd, String name) throws Exception {
String encPwd = encrypt(pwd);
String sql = "INSERT INTO user (id, pwd, name) VALUES (?, ?, ?)";
jdbcTemplate.update(sql, id, encPwd, name);
return "redirect:/login.jsp";
}
private String encrypt(String pwd) throws Exception {
MessageDigest md = MessageDigest.getInstance("SHA-256");
byte[] hash = md.digest(pwd.getBytes(StandardCharsets.UTF_8));
return Base64.getEncoder().encodeToString(hash);
}
}2. 비밀번호 암호화 (SHA-256)
2-1. 암호화 로직 재사용
로그인 시에도 같은 방식으로 비밀번호를 암호화하여 비교해야 합니다.
private String encrypt(String pwd) throws Exception {
MessageDigest md = MessageDigest.getInstance("SHA-256");
byte[] hash = md.digest(pwd.getBytes(StandardCharsets.UTF_8));
return Base64.getEncoder().encodeToString(hash);
}3. 로그인 실패 처리
3-1. 사용자 인증 로직 수정 (LoginController.java)
@Controller
public class LoginController {
@Autowired
JdbcTemplate jdbcTemplate;
@RequestMapping(value = "/login", method = RequestMethod.POST)
public String login(String id, String pwd, Model model, HttpSession session) throws Exception {
String sql = "SELECT * FROM user WHERE id = ?";
List<Map<String, Object>> users = jdbcTemplate.queryForList(sql, id);
if (users.isEmpty()) {
model.addAttribute("error", "존재하지 않는 사용자입니다.");
return "login";
}
Map<String, Object> user = users.get(0);
String encPwd = encrypt(pwd);
String dbPwd = (String) user.get("pwd");
int failCount = (Integer) user.get("fail_count");
if (failCount >= 5) {
model.addAttribute("error", "로그인 5회 이상 실패. 계정 잠김.");
return "login";
}
if (dbPwd.equals(encPwd)) {
jdbcTemplate.update("UPDATE user SET fail_count = 0 WHERE id = ?", id);
session.setAttribute("id", id);
return "redirect:/index.jsp";
} else {
jdbcTemplate.update("UPDATE user SET fail_count = fail_count + 1 WHERE id = ?", id);
model.addAttribute("error", "비밀번호가 일치하지 않습니다.");
return "login";
}
}
private String encrypt(String pwd) throws Exception {
MessageDigest md = MessageDigest.getInstance("SHA-256");
byte[] hash = md.digest(pwd.getBytes(StandardCharsets.UTF_8));
return Base64.getEncoder().encodeToString(hash);
}
}4. 로그인 화면에서 오류 메시지 출력
login.jsp 수정
<c:if test="${not empty error}">
<p style="color:red">${error}</p>
</c:if>5. 테스트 시나리오 요약
- 회원가입 페이지에서 회원 등록 (비밀번호는 암호화되어 저장됨)
- 올바른 비밀번호로 로그인 → 성공
- 틀린 비밀번호 5회 입력 → 계정 잠김
- 로그인 성공 시 실패 횟수 초기화
- 암호화된 비밀번호를 직접 DB에서 확인 가능
'Study > Java' 카테고리의 다른 글
| [커널아카데미] 백엔드 12기 9주차 - Spring MVC 기반 JSP 로그인 기능 개발기 (기초 → 컨트롤러 → 쿠키까지) (0) | 2025.05.25 |
|---|---|
| [커널아카데미] 백엔드 12기 6주차 - Oracle SQL 명령문 정리 (0) | 2025.05.04 |
| [커널아카데미] 백엔드 12기 5주차 - 디자인 패턴 심화, java 예제와 도식화 (0) | 2025.04.24 |
| [커널아카데미] 백엔드 12기 4주차 - 디자인 패턴 핵심 정리 (0) | 2025.04.21 |
| [커널아카데미] 백엔드 12기 3주차 - 인터페이스와 디자인 패턴 핵심 개념 (0) | 2025.04.14 |